Chapter 5: Synergy of Teleoperation and Human Data — Co-training
Summary
Co-training human data (Data B) with robot data (Data A) consistently outperforms either alone: EgoMimic +34–228%, EgoScale R²=0.9983 log-linear scaling, AoE 45%→95% (Close Laptop task), DEXOP 0.513>0.425. Furthermore, pi0 discovered emergent alignment of human-robot representations at scale. Most co-training studies use no tactile data; UMI-FT showed the first signal with wrist-level F/T sensing, but distributed tactile co-training remains entirely unexplored.
5.1 Introduction
Chapter 4 confirmed that Data B alone can reach ~70%. This chapter asks: "How much further can Data A push it?" This corresponds to TacTeleOp [#26] Hypothesis H2, the area with the richest existing evidence.
The core idea of co-training is simple: Data B teaches "what to do," Data A teaches "how this robot does it." Data B provides scale and realism; Data A provides executability and alignment.
5.2 Quantitative Evidence for Co-training
EgoMimic: "1 Hour of Hand > 2 Hours of Robot" (Georgia Tech, 2024)
EgoMimic [1] pioneered the co-training paradigm. It collected egocentric human data via Project Aria glasses and co-trained on a low-cost bimanual manipulator designed to minimize human-robot kinematic gap.
| Comparison | Result |
|---|---|
| 2 hr robot + 1 hr hand vs 3 hr robot (ACT) | +34–228% (per task) |
| Key finding | Human data shows higher asymptotic performance per unit time than robot data |
The key implication is that, per unit of time invested, human hand data reaches higher asymptotic performance as a scaling trend compared to teleoperation data. This is the most direct justification for TacTeleOp's "800-hour worker data collection" strategy.
Limitations: only 3 tasks validated, custom robot (general-purpose robots unvalidated), gripper/bimanual (dexterous hand unvalidated), no tactile.
EgoScale: Log-Linear Scaling Law (NVIDIA, 2026)
EgoScale [2] established the theoretical foundation for co-training. Pretraining a flow-based VLA on 20,854 hours of egocentric human video, followed by lightweight aligned human-robot mid-training:
| Metric | Value |
|---|---|
| Scaling law | Log-linear, R² = 0.9983 |
| vs no pretraining | +54% |
| Cross-robot transfer | Effective even for lower-DoF robots |
R² = 0.9983 means the relationship between human data volume and performance has near-perfect predictability. This allows pre-calculation of data investment ROI and provides a basis for estimating the expected effect of TacTeleOp's "800-hour investment."
Key question: Does tactile data follow the same log-linear scaling? EgoScale is vision-only. If tactile information density differs from visual, the scaling curve may differ — converging faster (less data needed) or slower (more data needed). This is one of TacTeleOp's core research questions (Chapter 10).
AoE: Dramatic Effect of Minimal Teleop + Abundant Human Data (2026)
AoE [3] most directly demonstrates TacTeleOp's scenario. Using a $20 smartphone neck mount for always-on egocentric collection and FLARE framework for co-training:
| Task | Teleop only (50) | + AoE (200 demos) |
|---|---|---|
| Pick and Place | 45.0% | 75.0% |
| Close Laptop | 45.0% | 95.0% |
| Fold Scarf | - | 10.0% (HW latency) |
| Push Bowl & Pour Seed | 0.0% | 20.0% |
The ablation result of 10 teleop + 200 AoE = 0%→55% (Close Laptop) shows that even minimal robot data can unlock the dramatic effect of abundant human data.
TacTeleOp connection: AoE's 50 teleop + 200 human → 45%→95% (Close Laptop task) directly validates TacTeleOp's "small Data A (50–100 teleop) + large Data B (50,000+ demos)" scenario. Pour Seed's 20% reveals vision-only co-training's contact-rich ceiling, the opportunity space for tactile addition.
DEXOP: Exoskeleton Data + Minimal Teleop (MIT, 2025)
DEXOP [4] [#10] mixed passive exoskeleton data with teleop data:

| Comparison | Success Rate |
|---|---|
| 160 exo + 40 teleop | 0.513 |
| 200 teleop only | 0.425 |
| Collection time difference | Half the time |
The pattern "non-robot data source + small robot data > pure robot data" aligns with EgoMimic and AoE.
pi0: Emergent Alignment at Scale (Physical Intelligence, 2025)
pi0 [5] [#2] pretrained a VLA on large-scale heterogeneous data (internet vision-language + robot + human video) and discovered emergent alignment — human-robot representations automatically converging without explicit alignment loss during co-finetuning.
| Metric | Value |
|---|---|
| Co-finetuning effect | 2× improvement across 4 scenarios |
| Emergent alignment | Human hand–robot gripper representations auto-converge |
This finding raises a fundamental question: With sufficient data scale, does the human-robot gap resolve automatically without explicit retargeting or alignment loss? If so, TacTeleOp's explicit cross-embodiment retargeting (Stage 2) may be unnecessary.
Three key constraints exist: (1) pi0 requires industrial-scale compute, infeasible for academic labs. (2) Observed only for grippers, unvalidated for dexterous hands. (3) Whether emergent alignment occurs for the tactile modality is unexplored. The third constraint is especially important — whether tactile emergent alignment occurs is a novel research question TacTeleOp can explore.
DexWM: World Model Approach (Meta FAIR, 2025)
DexWM [6] learned a world model from 900+ hours of human/robot video and performed dexterous manipulation via MPC. It achieved 83% zero-shot grasping success and +50% over Diffusion Policy.
The world model approach is another form of co-training: learning world dynamics from human data and applying them to robot action planning. Incorporating tactile state into TacPlay [#27]'s autonomous exploration world model could enable more accurate contact prediction.
UMI-FT: First Signal of Force/Torque-Aware Co-training (Columbia/Stanford, 2026)
UMI-FT [10] [#36] equipped the UMI (Chapter 4) handheld gripper with CoinFT — a 2 g, 20 mm diameter, 3 mm thick capacitive 6-axis force/torque sensor — on each finger, making it the first study to embed contact force information into in-the-wild demonstration data.
| Task | ACP (tactile+compliance) | DP+Force | DP only |
|---|---|---|---|
| Whiteboard wiping | 92% | 28% | 16% |
| Lightbulb insertion | 95% | 60% | 0% |
| Pumpkin skewering (wild) | 100% | — | 20% |
The key finding is the Adaptive Compliance Policy (ACP): it simultaneously predicts a reference pose (9D), virtual target pose (9D), stiffness scalar, gripper width, and grasp force target, switching between compliant control (low stiffness) during approach and rigid control (high stiffness) during insertion. This demonstrates that force information is decisive for contact-rich tasks where pure position control fails (DP only: lightbulb insertion 0%).
TacTeleOp connection: UMI-FT demonstrated that gripper-finger-level (2 sensors) force/torque sensing dramatically improves contact-rich co-training performance. However, UMI-FT's sensors amount to just two 6-axis F/T sensors at the wrist level, qualitatively different in information density from TacGlove's 5-finger, 24-channel distributed tactile. "If 2 sensors yield 0%→92%, what happens with 24-channel distributed tactile?" is the new question TacTeleOp will answer.
5.3 Formalizing the Co-training Effect
Synthesizing the above results:
Data B = scale + realism ("what to do, with what force")
Data A = executability + alignment ("how this robot does it")
Data A + Data B > Data A alone (EgoMimic, DEXOP)
Data A + Data B > Data B alone (X-Sim, EgoZero's 70% ceiling)
Small A + Large B ≈ optimal (AoE, DEXOP)
EgoScale's log-linear scaling means this effect increases predictably with Data B volume.
5.4 Comparative Analysis
| Study | Human Data | Robot Data | Method | Key Result | Tactile |
|---|---|---|---|---|---|
| EgoMimic | Aria (visual) | teleop | Co-train | +34–228% | No |
| EgoScale | 20,854 hr ego | mid-train | Pretrain+finetune | +54%, R²=0.9983 | No |
| AoE | 200 demos | 50 teleop | Co-train (FLARE) | 45→95% (Close Laptop) | No |
| DEXOP | 160 exo | 40 teleop | Mixed training | 0.513>0.425 | No |
| pi0 | internet+human | robot | Co-finetuning | 2×, emergent | No |
| DexWM | 829 hr human | 100 hr robot | World model | 83% grasping | No |
| UMI-FT | In-the-wild demos (with force) | 0 | Diffusion+ACP | 92% wiping, 95% bulb | Wrist F/T |
Apart from UMI-FT, all studies use no tactile data, and even UMI-FT is limited to one 6-axis F/T sensor per gripper finger (2 total). Distributed tactile co-training is completely unexplored. This is TacTeleOp's core opportunity.
5.5 Key Discussion: The Unexplored Domain of Tactile Co-training
That co-training works is an established fact. UMI-FT opened the first breakthrough with wrist-level force/torque sensing (whiteboard wiping 16%→92%), but the vast majority of current co-training remains vision-only, and how co-training behaves with distributed tactile remains an open question:
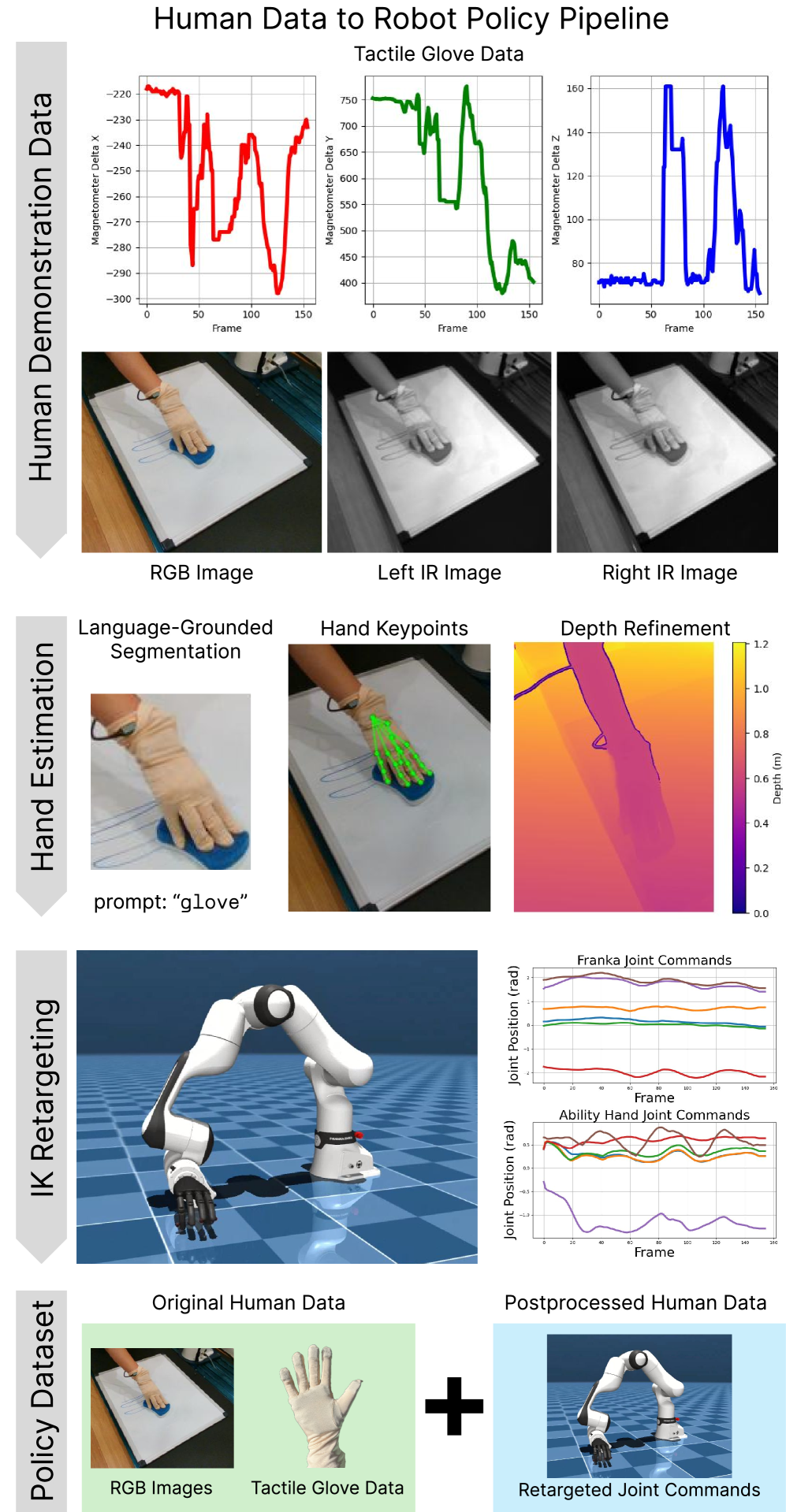
- Tactile scaling law: Does EgoScale's visual log-linear hold for tactile? If tactile has higher information density, it may converge faster — large effect from less data.
- Tactile emergent alignment: Does visual emergent alignment observed in pi0 occur for tactile? Could OSMO's Embodiment Bridge accelerate it?
- Optimal ratio: What is the optimal mixing ratio of Data B (with tactile) and Data A? Same as vision co-training?
- Contact-rich differentiation: As vision-only co-training plateaued at 20% on AoE Pour Seed, and UMI-FT overcame this with 2 F/T sensors, does 24-channel distributed tactile yield further improvement?
UMI-FT provided the first quantitative evidence that "force information is decisive for contact-rich co-training." However, UMI-FT's sensor configuration (one 6-axis F/T per gripper finger) and TacGlove's distributed tactile (5-finger, 24-channel) are qualitatively different in information density. "How do co-training's scaling law and performance ceiling change when distributed tactile is included?" remains an open question, and answering it constitutes TacTeleOp's core scientific contribution.
5.6 Connection to Our Direction
TacTeleOp extends the co-training effects confirmed in this chapter to the tactile domain:
- Stage 1 (B pretrain): Pretrain on 800 hours of tactile+visual worker data
- Stage 2 (Retargeting): UniTacHand [#16] UV map-based tactile alignment
- Stage 3 (A fine-tune): Fine-tune with 50–100 teleop demos
If EgoMimic showed the effect of vision co-training, TacTeleOp aims to show the effect of tactile co-training. If EgoScale demonstrated the vision scaling law, TacTeleOp explores the tactile scaling law (Chapter 8, Chapter 10).
References
- Kareer, S., et al. (2024). EgoMimic: Scaling Imitation Learning via Egocentric Video. arXiv. https://arxiv.org/abs/2410.24221 scholar
- Zheng, R., et al. (2026). EgoScale: Egocentric Video Pretraining for Scalable Robot Learning. arXiv. https://research.nvidia.com/labs/gear/egoscale/ scholar
- Yang, B., et al. (2026). AoE: Always-on Egocentric Data Collection for Robot Learning. arXiv. scholar
- Fang, H.-S., et al. (2025). DEXOP: Dexterous Manipulation with Passive Exoskeleton. IEEE RA-L. #10 scholar
- Physical Intelligence (2025). pi0: A General-Purpose Robot Policy. arXiv. #2 scholar
- Goswami, R. G., et al. (2025). DexWM: Dexterous World Models from Human and Robot Data. arXiv. scholar
- Yang, R., et al. (2025). EgoVLA: Egocentric Vision-Language-Action Model. arXiv. scholar
- PhysBrain (2025). Egocentric2Embodiment Pipeline. arXiv. scholar
- RoboWheel (2024). HOI-Based Cross-Embodiment Robot Learning. arXiv. scholar
- Chi, C., et al. (2026). In-the-Wild Compliant Manipulation with UMI-FT. arXiv. #36 scholar