Chapter 6: Embodiment Gap 해소 — 리타게팅과 정렬
요약
인간-로봇 embodiment gap은 세 차원으로 분해된다: 기구학, 시각, 촉각. 시각 gap 해법은 가장 성숙하고(Mirage, H2R, Masquerade), 기구학 gap은 residual RL로 유망한 결과를 보이며(DexH2R +40%), 촉각 gap은 OSMO의 shared platform이 유일한 시도로 거의 미탐색 상태이다. "촉각 잔차 학습"은 기존 연구에서 시도된 적 없으며, 이것이 TacPlay [#27]의 핵심 novelty 공간이다.
6.1 도입
사람 손 데이터(Data B)를 로봇 정책으로 전환하는 과정에서 가장 근본적인 장벽은 embodiment gap — 인간과 로봇의 신체적 차이이다. 인간은 5개의 20+ DoF 손가락을 가지지만, 로봇 핸드는 3~5개의 3~4 DoF 손가락을 가진다. 외관이 다르고, 센서 분포가 다르며, 동역학이 다르다.
이 gap을 세 차원으로 분해하면 각각의 성숙도와 미해결 정도가 드러난다.
6.2 기구학 Gap: 관절 구조와 운동 범위의 차이
DexH2R: Residual RL (2024)
DexH2R[1]은 task-oriented residual RL로 기구학 gap을 해소한다. 인간 hand motion을 로봇으로 retarget한 결과(primitive actions)에 residual policy를 RL로 학습하여 오류를 보정한다.
| 지표 | 수치 |
|---|---|
| Grasping 성공률 | 70.9% |
| Whole trajectory 완수 | 52.7% |
| vs retargeting-only | +~40% |
핵심 결과: retargeting만으로는 30%대에 머무르지만, residual RL을 추가하면 70.9%로 상승한다. 이 +40%p의 gap이 residual policy가 보정하는 양이다.
TacPlay 연결: \pi_{robot} = \pi_{human} + \Delta_{residual}이라는 TacPlay의 잔차 정책 구조는 DexH2R의 접근을 직접 계승한다. 차이는 DexH2R이 시각 기반 task-oriented reward를 사용하는 반면, TacPlay는 촉각 기반 reward를 사용한다는 점이다.
한계: 시뮬레이션만, task-specific reward 수동 설계 필요, cross-task 일반화 미검증.
ManipTrans: Bimanual Residual Learning (CVPR 2025)
ManipTrans [2]은 generalist trajectory imitator pretrain + specialist residual module fine-tune로 bimanual dexterous manipulation transfer를 달성했다. DexManipNet(3.3K episodes, 1.34M frames)을 데이터로 활용하여 SOTA success rate, fidelity, efficiency를 보고했다.
DexH2R과 함께 residual learning의 유효성을 지지하지만, 역시 시뮬레이션만이며 촉각 정보를 사용하지 않는다.
Park et al.: Learning to Transfer Human Hand Skills (CMU/SNU, 2025)
Park et al.[2]은 인간-로봇 공통 motion manifold를 학습하여 retargeting에 활용했다. 인간 mocap과 로봇 텔레오퍼레이션 데이터로 pseudo-supervision triplet을 생성하고, 이를 통해 3D 공간에서 인간 손, 로봇 핸드, 물체의 움직임을 매핑하는 joint motion manifold를 학습한다. 전체 성공률 0.59 vs fingertip matching baseline 0.39를 달성했다. CMU/SNU(주영래 교수 연구실) 공동연구이다.
ACT-1의 Embodiment Alignment: 하드웨어 Co-Design (Sunday Robotics, 2025)
ACT-1 [9] [#29]은 가장 극단적인 기구학 gap 해소 전략을 제시했다: 로봇 손과 인간 글러브를 정확히 동일한 기하(geometry)와 센서 레이아웃으로 공동 설계(co-design)하여 기구학 변환 자체를 제거한다. Skill Transform은 남은 키네마틱+비주얼 gap을 정렬하여 90% 변환 성공률을 달성했다. 이 접근은 기구학 retargeting의 필요성을 하드웨어 수준에서 원천적으로 제거한다는 점에서 DexH2R이나 ManipTrans의 소프트웨어적 접근과 질적으로 다르다.
다만 Skill Capture Glove는 gripper 형태(2-DoF)이며, 촉각 센서를 포함하지 않아 dexterous hand(20+ DoF)와 분산 촉각이 필요한 태스크에서의 효과는 미검증이다. 또한 co-design은 기존 로봇 하드웨어에 적용할 수 없다는 구조적 한계가 있다 — 새로운 로봇 손을 도입할 때마다 글러브를 재설계해야 한다.
6.3 시각 Gap: 인간 손 vs 로봇 손의 외관 차이
시각 gap 해법은 세 차원 중 가장 성숙하다.
Mirage: Cross-Painting (UC Berkeley, RSS 2024)
Mirage [4]는 테스트 시 target robot을 source robot으로 inpainting하여 visual gap을 zero-shot으로 해소한다. 3종 로봇 × 4태스크에서 minimal performance degradation으로 전이에 성공했다. 핵심 ablation: cross-painting 제거 시 성능 급락 → visual gap이 주요 병목임을 실증.
한계: gripper 기반만, dexterous hand 미검증, 실시간 처리 비용.
H2R: Human→Robot Video Augmentation (2025)
H2R[5]은 인간 비디오에서 3D hand keypoint를 추출하고, 시뮬레이션에서 로봇 모션을 합성하여 egocentric 비디오에 합성한다. Ego4D/SSv2에서 1M-scale 데이터셋을 생성하여 시뮬레이션에서 +5.0~10.2%, 실세계에서 +6.7~23.3% 향상을 달성했다. UR5+Gripper, UR5+LEAP Hand, Franka 등 다양한 로봇에서 효과적이었다.
Masquerade: Robotized Demonstrations (2025)
Masquerade [6]는 in-the-wild 인간 비디오를 "robotized" 데모로 변환한다. 인간 팔을 inpainting으로 제거하고 bimanual robot을 오버레이한 675K 프레임으로 visual encoder를 pretrain한 뒤, 50 robot demos/task로 diffusion policy를 fine-tune했다.
| 비교 | 결과 |
|---|---|
| vs baselines | 5~6x outperforms |
| Scaling | 로그적 (edited 데이터 양 ↑) |
Ablation에서 robot overlay와 co-training 모두 indispensable함을 확인했다. "log scaling with edited data"는 TacTeleOp [#26]의 데이터 규모 효과 예측에도 참조할 만하다.
UMI: 물리적 등가(Physical Equivalence) (Chi et al., RSS 2024)
UMI [10] [#35]는 시각 gap을 소프트웨어가 아닌 하드웨어로 해소한다. 인간이 로봇과 동일한 핸드헬드 그리퍼($371)를 쥐고 시연하므로, 시연 영상에 로봇 end-effector가 그대로 나타나 외관 차이가 원천적으로 제거된다. 155도 GoPro 피쉬아이 카메라와 relative trajectory action representation으로 cross-robot 전이를 지원한다.
Mirage/H2R/Masquerade가 '인간 → 로봇 외관 변환'이라면, UMI는 '애초에 같은 외관'이라는 물리적 해결책이다. Franka FR2로 제로샷 전이 시 90% 성공률을 보고했다.
한계: gripper 전용 인터페이스이므로 dexterous hand에는 적용 불가하며, 인간이 gripper를 쥐고 시연하므로 손가락 수준의 조작 데이터는 수집할 수 없다. ACT-1과 유사하게 하드웨어 등가 전략이지만, UMI는 시각 차원에, ACT-1은 기구학 차원에 초점을 둔다.
6.4 촉각 Gap: 감각 밀도와 분포의 차이
촉각 gap은 세 차원 중 가장 미해결이며, 이것이 TacPlay의 핵심 기회 영역이다.
현황: OSMO가 유일
인간 피부는 손에 약 17,000개의 기계수용기를 가지지만, 현재 촉각 글러브는 12~548개의 센서를 탑재한다. 이 밀도 불일치 자체는 UV map 정규화(UniTacHand [#16])나 shared platform(OSMO [#18])으로 부분적 해소가 가능하다.
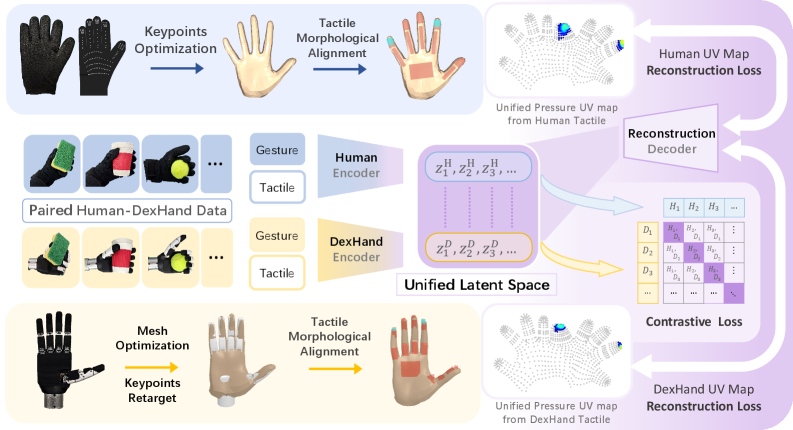
그러나 더 근본적 문제는 동일한 조작 동작에서도 기구학 차이 때문에 접촉 패턴이 다르다는 것이다. 인간이 5손가락으로 컵을 잡을 때의 촉각 패턴과, 4손가락 로봇(LEAP Hand)이 같은 컵을 잡을 때의 촉각 패턴은 근본적으로 다르다 — 접촉 면적, 힘 분포, 손가락별 역할이 모두 다르기 때문이다.
OSMO [7]는 동일 물리적 글러브를 인간과 로봇에 모두 장착하여 이 문제를 물리적으로 우회한다. 같은 센서에서 데이터가 생성되므로 센서 특이성 문제는 사라진다. 그러나 이것은 수동적 정렬이다 — 데이터를 같은 공간에 놓을 뿐, 기구학 차이에서 오는 패턴 차이를 보정하지는 않는다.

EquiTac: 촉각 등변 표현 (2025)
EquiTac[11] [#37]은 촉각 gap에 대한 구조적 접근을 제시했다. GelSight 센서의 표면 법선맵이 물체 회전에 대해 SO(2)-등변 대칭을 가진다는 사실을 활용하여, C₈-등변 CNN으로 촉각 데이터를 처리한다. 이를 통해 학습하지 않은 방향에서도 제로샷 일반화가 가능하며(각도 추정 오차 2.9도), 10개 시연만으로 90% 성공률을 달성한다.
비록 현재는 2-DoF 그리퍼의 yaw 보정에 한정되어 있지만, 촉각 데이터의 기하학적 구조를 활용한 cross-orientation transfer라는 개념은 dexterous hand 촉각 gap에도 확장 가능한 원리를 제시한다. OSMO가 센서 하드웨어를 통일하는 '물리적 정렬'이라면, EquiTac은 데이터의 기하학적 대칭성을 활용하는 '구조적 정렬'이다. 다만 cross-embodiment transfer(인간→로봇)가 아닌 단일 로봇 내의 orientation 일반화이므로, 촉각 embodiment gap 해소와는 직접적 연결보다는 원리적 시사점을 제공한다.
촉각 잔차 학습: 아무도 시도하지 않은 영역
DexH2R이 기구학 잔차를 residual RL로 학습하여 +40%를 달성한 것과 마찬가지로, 촉각 잔차도 학습 가능한 대상이다. 인간과 로봇의 기구학 차이에서 오는 촉각 패턴의 체계적 편차(systematic bias)는, 물체나 태스크에 무관한 물리적 상수에 가까울 수 있다 — 같은 로봇은 항상 같은 방식으로 기구학적으로 다르기 때문이다.
이 가설이 맞다면, 한 태스크에서 학습한 촉각 잔차를 다른 태스크에 전이(cross-task generalization)할 수 있다. 이것은 DexH2R의 task-specific 잔차와 대비되는 TacPlay의 핵심 차별점이다.
그러나 이 가설을 뒷받침하는 기존 실험 증거는 거의 없다. DexH2R의 잔차가 task-specific인지 cross-task 일반화 가능한지조차 검증되지 않았다. 이것은 TacPlay의 가장 야심적이면서 가장 위험한 claim이다 (Chapter 9).
6.5 세 차원의 성숙도 비교
| Gap 유형 | 해법 | 대표 논문 | 성숙도 |
|---|---|---|---|
| 시각 | Cross-painting | Mirage | 높음 |
| 시각 | Robot overlay | H2R (+6.7~23.3%) | 높음 |
| 시각 | Robotized demos | Masquerade (5~6x) | 높음 |
| 시각 | 물리적 등가 | UMI (90%, gripper) | 높음 |
| 기구학 | Residual RL | DexH2R (+40%) | 중간 (sim only) |
| 기구학 | Motion manifold | Park et al. (0.59) | 초기 |
| 기구학 | Bimanual residual | ManipTrans (SOTA) | 중간 (sim only) |
| 기구학 | 하드웨어 co-design | ACT-1 (90%, 2-DoF) | 중간 (gripper only) |
| 촉각 | Shared platform | OSMO (유일) | 매우 초기 |
| 촉각 | 등변 표현 | EquiTac (90%, 10 demos) | 초기 (단일 로봇) |
| 촉각 | Residual learning | 미존재 | 미탐색 |
이 표가 보여주는 메시지는 명확하다: 촉각 embodiment gap은 가장 비어 있는 영역이다. 시각에는 Mirage, H2R, Masquerade 등 다수의 효과적 해법이 있고, 기구학에는 DexH2R과 ManipTrans가 유망한 결과를 보이지만, 촉각은 OSMO의 수동적 shared platform이 전부이다.
6.6 핵심 논의
TacTeleOp의 시각 gap 전략
TacTeleOp은 시각 gap 해소에 기존의 성숙한 해법을 활용할 수 있다. Mirage의 cross-painting이나 H2R의 robot overlay를 TacTeleOp의 시각 데이터 처리에 적용하면, 시각 gap은 이미 해결된 문제로 처리 가능하다. TacTeleOp의 contribution은 시각 gap이 아닌, 촉각 gap과 촉각 co-training에 집중되어야 한다.
TacPlay의 촉각 gap 전략
TacPlay는 OSMO의 수동적 Embodiment Bridge를 능동적 학습으로 확장한다:
- Phase 1: 인간의 촉각 패턴을 "촉각 레시피"로 추출 (= OSMO의 데이터 수집)
- Phase 2: 동일 글러브를 로봇에 장착하고, 인간 촉각 패턴을 "목표"로 RL 실행 (= DexH2R의 residual RL을 촉각으로 확장)
- Phase 3: 학습된 촉각 잔차로 배치 (= DexH2R의 \pi_{human} + \Delta_{residual})
이 파이프라인은 OSMO(shared platform) + DexH2R(residual RL)의 새로운 조합이다. 각 구성요소는 기존에 있지만, 이 조합은 시도된 적 없다 (Chapter 9).
Masquerade의 시사점
Masquerade [6]의 두 가지 발견이 TacTeleOp에 시사하는 바가 크다:
- Log scaling: 편집된 인간 데이터 양과 성능이 로그적 관계. 촉각 데이터에서도 동일 패턴이라면, 초기 수백 시간의 데이터가 가장 큰 효과를 줄 것이다.
- Co-training indispensable: 순수 인간 데이터(robotized)만으로는 부족하고, robot data와의 co-training이 필수. TacTeleOp의 Data A + Data B 혼합 전략을 지지한다.
6.7 우리의 방향과의 연결
본 장의 분석에서 TacGlove/TacTeleOp/TacPlay의 포지션이 명확해진다:
- 시각 gap: 이미 해결된 문제. 기존 해법(Mirage, H2R) 활용.
- 기구학 gap: Residual RL이 유망. TacTeleOp Stage 2에서 기존 retargeting 기법 활용.
- 촉각 gap: 가장 비어 있는 영역. TacPlay가 촉각 잔차 학습으로 개척.
Part II를 종합하면: Data B만으로 70% 가능하나 contact-rich에서 한계(Chapter 4), co-training으로 95%까지 가능하나 촉각 미포함(Chapter 5), embodiment gap의 촉각 차원은 거의 미해결(Chapter 6). 이것이 Part III에서 제안하는 TacGlove(Chapter 7), TacTeleOp(Chapter 8), TacPlay(Chapter 9)의 동기이다.
참고문헌
- DexH2R (2024). Task-Oriented Residual RL for Dexterous Manipulation Transfer. arXiv. scholar
- Li, et al. (2025). ManipTrans: Efficient Bimanual Dexterous Manipulation Transfer via Residual Learning. CVPR 2025. scholar
- Park, S., et al. (2025). Learning to Transfer Human Hand Skills for Robot Manipulations. arXiv:2501.04169. scholar
- Chen, L. Y., et al. (2024). Mirage: Cross-Embodiment Zero-Shot Transfer via Cross-Painting. RSS 2024. scholar
- H2R (2025). Human-to-Robot Video Augmentation for Pretraining. arXiv. scholar
- Lepert, et al. (2025). Masquerade: Scaling In-the-Wild Human Video to Bimanual Robot Policy Learning. arXiv. scholar
- Yin, J., et al. (2025). OSMO: A Large-Scale Tactile Glove. arXiv. https://arxiv.org/abs/2512.08920 #18 scholar
- Liu, V., et al. (2025). EgoZero: Smart Glasses to Robot Policy. arXiv. scholar
- Sunday Robotics (2025). ACT-1: Robot Foundation Model with Skill Transform. #29 scholar
- Chi, C., et al. (2024). UMI: Universal Manipulation Interface. RSS 2024. #35 scholar
- EquiTac (2025). Tactile Equivariance for Cross-Orientation Transfer. arXiv. #37 scholar